Consultant
· 6 min read
TL;DR
Our study, sparked by a content management system (CMS) migration anomaly discovered that certain attributes caused Google to ignore canonical tags. Read on to learn our methodology, data, and practical recommendations to ensure your canonical link tags work as intended.
Introduction
A correct implementation of canonical link tags is essential for effective indexing of a website, as they help manage content duplication and direct search engines to the preferred version of a webpage.
This study focuses on how search engines, particularly Google, interpret canonical link tags with additional attributes other than rel="*" and href="*"
Our research was prompted by an anomaly observed during a CMS migration, where Google Search Console failed to recognise canonical link tags.
Research Objectives
This study aims to address the following questions:
- What is Google's policy on processing canonical link tags with additional attributes?
- Which specific attributes cause Google to disregard canonical link tags?
- Are there any other/undocumented attributes that affect canonical link tag interpretation?
- How do these findings impact current SEO best practices?
- Do other search engines treat canonical link tags with extra attributes similarly to Google?
- What measures can website owners and developers implement to ensure their canonical link tags are respected by search engines?
Background
During a CMS migration project, we encountered an anomaly where the Google Search Console inspector tool failed to detect canonical link tags that were visibly present in both the raw HTML source and the rendered Document Object Model (DOM). Using the Google Search Console inspector showed that the canonical was not present, even though it was present:
1<link rel="canonical" crossorigin="anonymous" media="all" href="<https://example.com/category/123-slug-here>" />This observation led to an investigation of Google's documentation, which revealed a recent update (February 15, 2024) clarifying the extraction of rel="canonical" annotations:
The rel="canonical" annotations help Google determine which URL of a set of duplicates is canonical. Adding certain attributes to the link element changes the meaning of the annotation to denote a different device or language version.
This is a documentation change only; Google has always ignored these rel="canonical" annotations for canonicalisation purposes. The documentation explicitly mentioned four attributes that, when present, cause Google to disregard the canonical link tag: hreflang, lang, media, and type.
Google supports explicit rel="canonical" link annotations as described in [RFC 6596]. rel="canonical" annotations that suggest alternate versions of a page are ignored; specifically, rel="canonical" annotations with hreflang="lang_code", lang, media, and type attributes are not used for canonicalization. Instead, use the appropriate link annotations to specify alternate versions of a page; for example <link rel="alternate" hreflang="lang_code" href="url_of_page" /> for language and country annotations.
Great! We could confirm this was indeed an expected behaviour. But it also raised several questions, like: Are there other/undocumented attributes that may cause Google to entirely ignore the canonical link tag? How widespread is the usage of these problematic attributes? And, are there tools that already flag these attributes as being potentially problematic?
Methodology
Our research methodology comprised the following steps:
- Web Scraping: We extracted canonical link tags from the top 1 million websites.
- Data Cleaning: After filtering for valid responses, we analysed 595,517 domains.
- Attribute Analysis: We identified and cataloged 210 unique attribute names used in canonical link tags.
- Experimental Setup: We developed a Vercel application to generate 568 URLs with various attribute permutations (available at https://canonical-research.vercel.app)
- Testing: We utilised Google Search Console's live URL inspection tool to verify if Google recognises these as self-declared canonicals—we wanted to assess simply if Google recognises the presence of a canonical link tag, and not if it chose to respect it or not after evaluating the contents on a page.
- Data Collection: Due to GSC's daily inspection limit, we conducted tests over a one-week period.
Results
Attribute Frequency
Our analysis identified the top 10 most common attributes found in canonical link tags that Google does not flag as problematic:
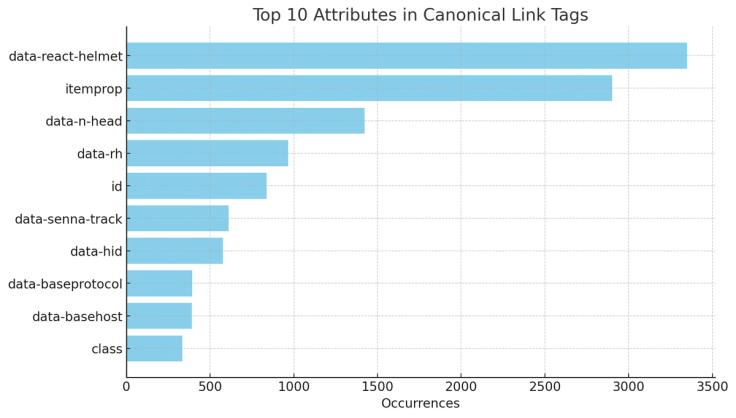
- data-react-helmet (3,348 occurrences)
- itemprop (2,902 occurrences)
- data-n-head (1,423 occurrences)
- data-rh (967 occurrences)
- id (837 occurrences)
- data-senna-track (610 occurrences)
- data-hid (576 occurrences)
- data-baseprotocol (393 occurrences)
- data-basehost (392 occurrences)
- class (335 occurrences)
Within our gathered dataset, the four attributes in canonical link tags known to cause issues ranked as follows:
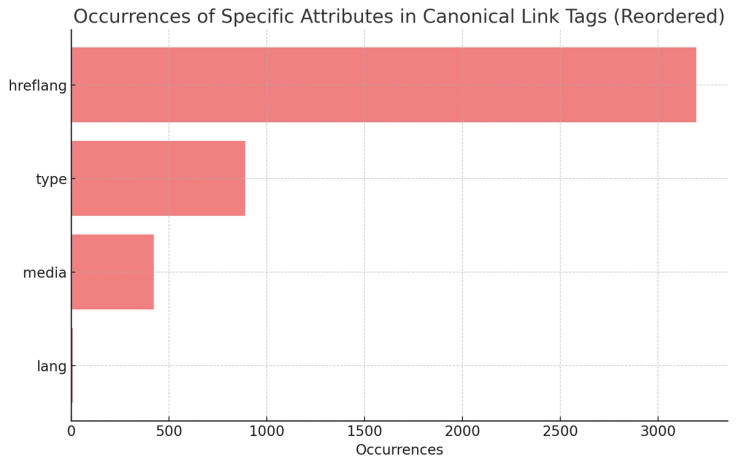
- hreflang (3196 occurrences)
- type (889 occurrences)
- media (421 occurrences)
- lang (8 occurrences)
Google's Interpretation
Our testing yielded the following results:
- Google ignores attributes not explicitly mentioned in their documentation and these don’t affect the search engine’s ability to correctly identify canonical link tags.
- Canonical link tags containing hreflang, lang, media, or type attributes were not identified as self-canonical in the GSC inspector and the entire canonical tag is ignored.
- The presence of multiple attributes or various combinations did not alter this behaviour, as long as none of the attributes is one of the listed above.
SEO Tool Limitations and Implications
A significant finding from our study is that many popular SEO crawling tools do not flag issues related to problematic attributes in canonical link tags. This oversight can lead to undetected canonicalisation problems, impacting the effectiveness of canonical implementations. It's crucial to be aware of this limitation and take proactive measures to manually verify your canonical link tags using tools like Google Search Console's URL inspection tool, or building custom systems that specifically monitor the canonical link tags and look for these specific attributes.
Verifying
Cross-Search Engine Comparison
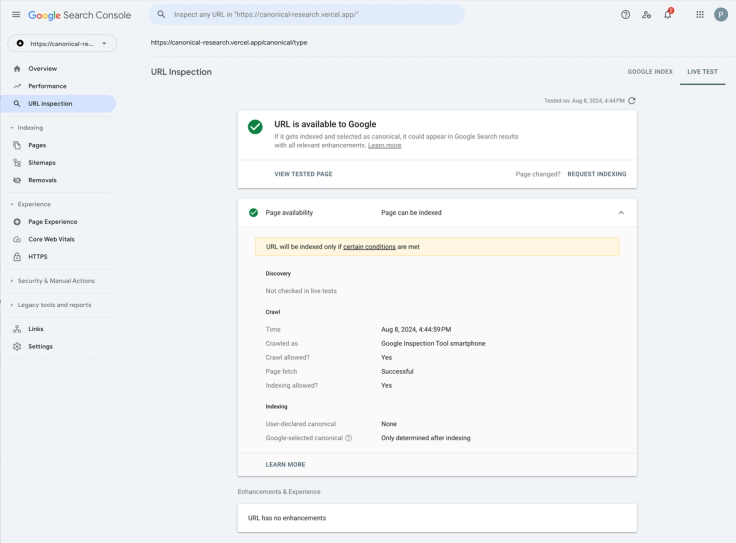
We captured the URL inspection testing using Google and Bing Webmaster tools. Example of Google Search Console Live Testing for a URL with a canonical containing problematic attributes (note how “None” is displayed for the User-declared canonical):
Google Search Console Live Testing for a URL with a canonical not containing problematic attributes:
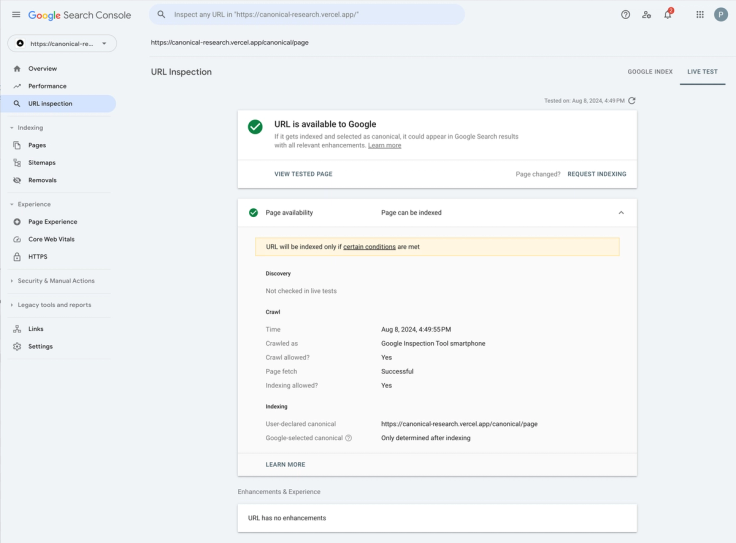
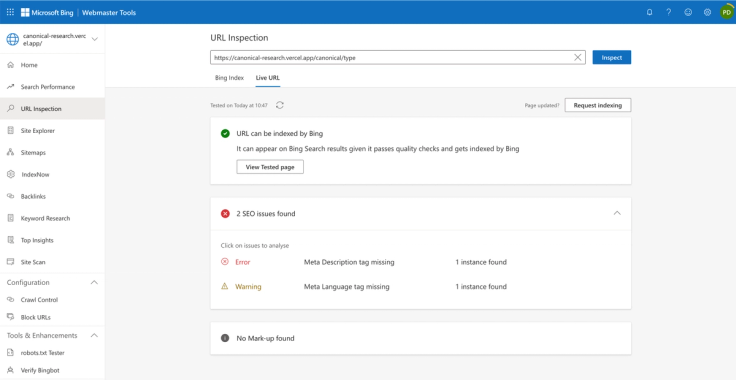
While Google reports “None” for the User-declared canonical, hinting it didn’t recognise a canonical link tag, in Bing Webmaster Tools, the live URL inspection didn’t report the presence nor flag issues with the canonical for any URLs in our testing set.
Bing Webmaster Tools live URL inspection test for a URL with a canonical containing problematic attributes (no data is shown regarding canonical link tags):
Bing Webmaster Tools live URL inspection test for a URL with a canonical not containing problematic attributes:
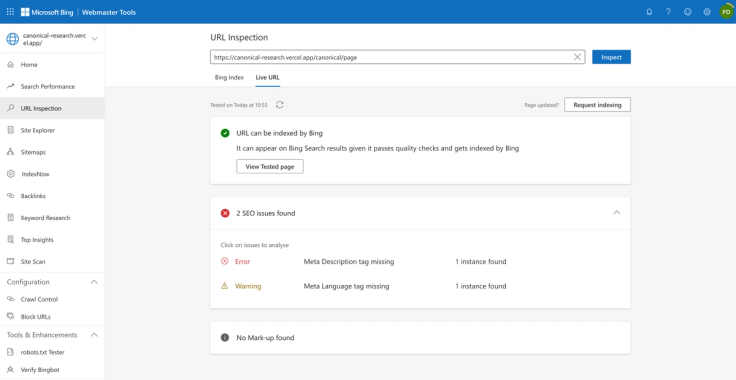
While our study focused primarily on Google and Bing's interpretation of canonical link tags, further research around actual crawling and indexing may be required to determine if other search engines like DuckDuckGo, Naver, handle canonical link tags with attributes in a similar manner.
Recommendations
Based on our findings, we propose the following recommendations:
- Simplify canonical link tag HTML as much as possible, avoiding unnecessary attributes. The only attributes used should be rel and href.
- If additional data must be included on the canonical tag, use data-* attributes.
- We highly recommend avoid using common attribute names such as id, name, or content in canonical link tags, as they may become reserved words in the future.
- Setup CICD checks to identify if additional attributes are added.
- Verify the effectiveness of your canonical link tags using Google Search Console's URL inspection tool, or custom-built systems.
Conclusion
Our research highlights critical findings regarding the interpretation of canonical link tags by Google, especially when additional attributes are present. Key takeaways include:
- Certain attributes in canonical link tags, such as hreflang, lang, media, and type, cause Google to disregard them.
- Many common SEO tools do not flag these problematic attributes, leading to potential oversight in canonicalisation.
- To ensure an effective indexing process, it is crucial to simplify canonical link tags by avoiding unnecessary attributes and regularly verifying them using tools like Google Search Console.
These are nuances important to understand, in order to stay updated with search engine guidelines and a healthy website in search results, regardless of the insights provided by SEO tools.