Screaming Frog customers have been noticing inconsistencies between the company’s own robots.txt tester tool and the one in Google Search Console.
This was originally noticed back in 2016 by Giuseppe Pastore. Liam Sharp, a developer behind Screaming Frog SEO Spider, shared his thoughts into the Google Search Console (GSC) Tester Inconsistencies. After a series of experiments, he concluded that the robots.txt tester, in fact, is not reliable.
He believed the reason behind this is because the tester follows a different set of rules to those followed by the Googlebot which accepts the UTF-8, upper and lowercase percentage-escaped forms of URLs in a robots.txt file.
We decided to look into this further, by setting up a disallow rule on our merj.com/robots.txt file for the percentage-escaped version of the UTF-8 path /able_✓ as described in the RFC 3986.
User-Agent: *
Disallow: /able_%e2%9c%93To start with, we tried testing the UTF-8 encoding which showed as being “ALLOWED”
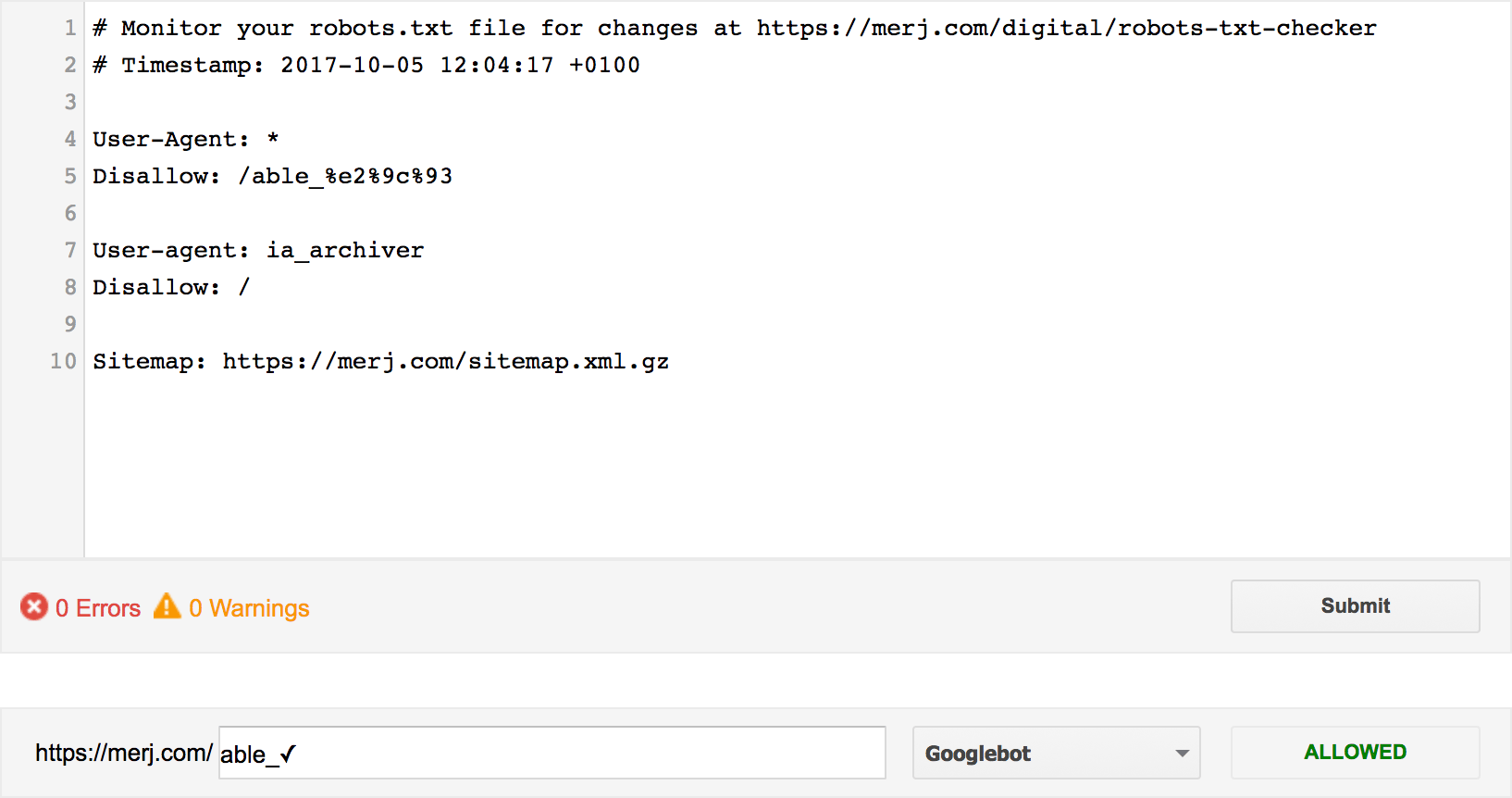
With that test failing, we needed to percentage-escaped the URI path, so we used Ruby’s IRB interpreter and added the cgi module:
require 'cgi'The next step was to use the CGI.escape method on the string to get the percentage-coded encoded version:
CGI.escape("/able_✓")
=> "/able_%e2%9c%93"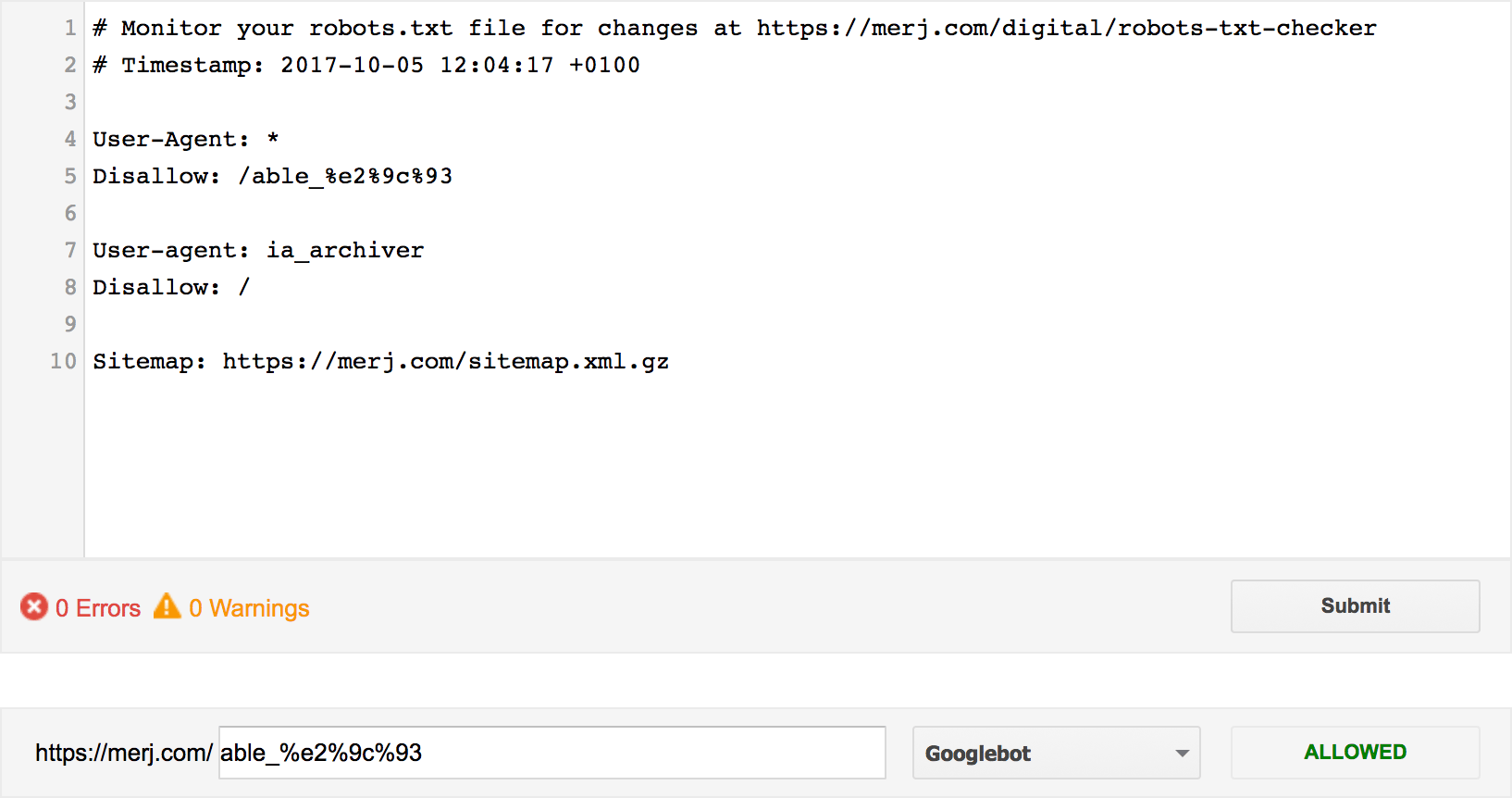
Unfortunately, there was still no luck at this point, as it was still showing as “ALLOWED”. From my own experience as a developer, I’ve often seen URIs with double percentage-encoding.
The next step was to try to escape the already escaped version (double encoding):
CGI.escape("/able_%e2%9c%93)
=> "/able_%25e2%259c%2593"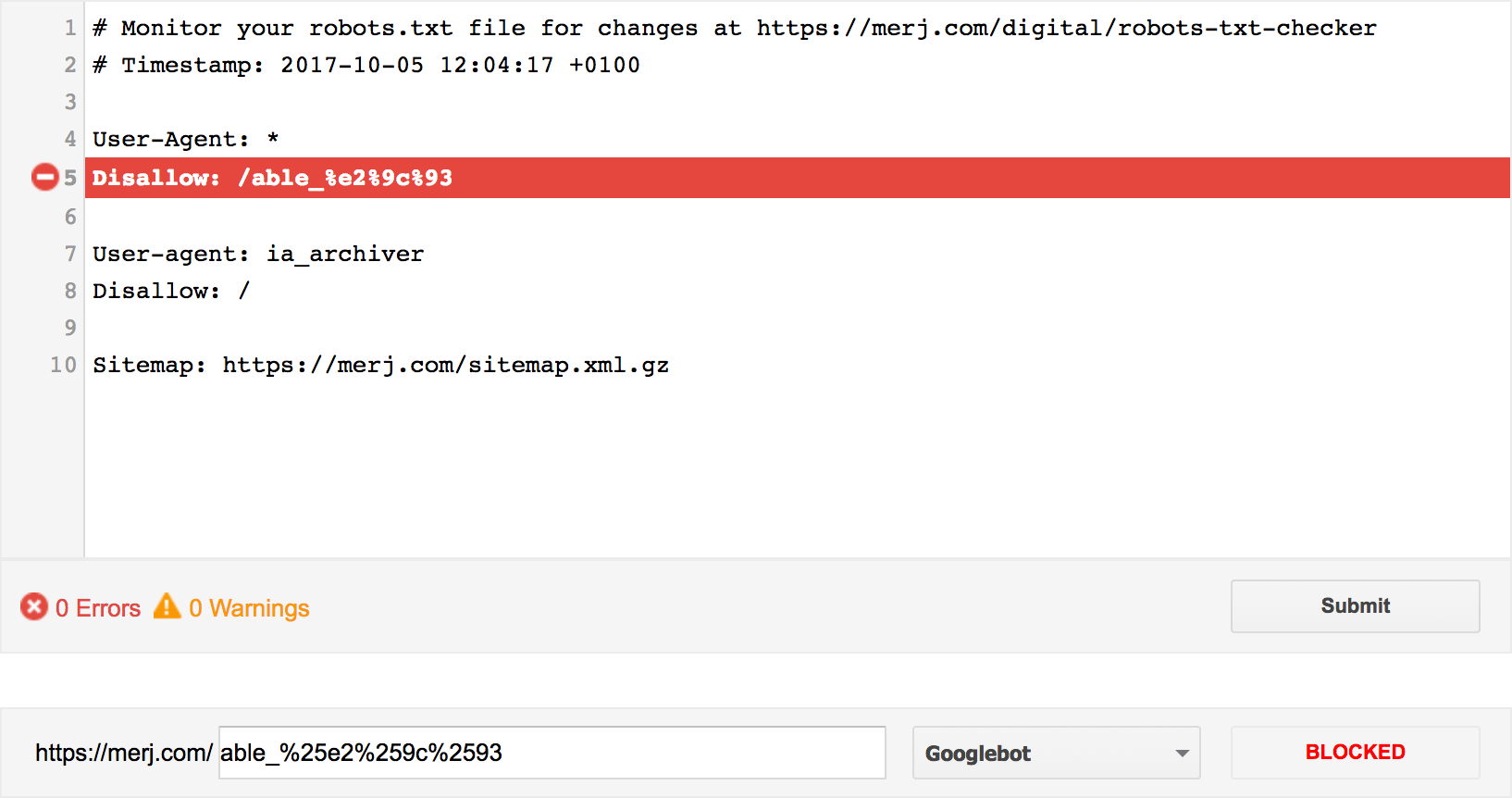
Success! It shows as “BLOCKED”.
Google Search Console is trying to escape the percentage-escaped string. This is because Google expects UTF-8 as an input rather than percentage-escaped paths.
To show that this works in reverse, use the CGI.unescape method to unescape the URI path.
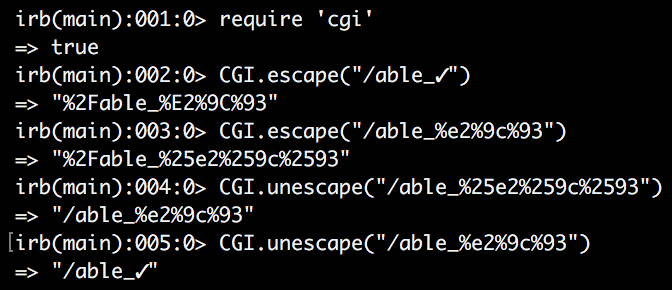
CGI.unescape("/able_%25e2%259c%2593")
=> "/able_%e2%9c%93"
CGI.unescape("able_%e2%9c%93")
=> "/able_✓"All together it looks like this:
It’s worth noting that if you decide to batch escape your entire URL, including protocol, then it’ll turn out like this:
CGI.escape("https://merj.com/able_%e2%9c%93")
=> "https%3A%2F%2Fmerj.com%2Fable_%25e2%259c%2593"I’ve created a simple script that will allow you to batch escape or unescape your URLs. You can grab the script from the GIST below:
#!/usr/bin/env ruby
require 'cgi'
CGI_METHODS = %w[escape unescape]
USAGE = "usage: #{File.basename(__FILE__)} input output type"
input = ARGV[0]
output = ARGV[1]
type = ARGV[2]
if !output || !input ||!File.exist?(input) || !CGI_METHODS.include?(type)
$stderr.puts USAGE
exit(1)
end
begin
File.open(output, 'w') do |file|
IO.readlines(input).each do |line|
file.puts(CGI.send(type, line))
end
end
endAlways make sure that when testing your URLs, you use UTF-8 and Google will handle the escaping/unescaping.